时令 发自 凹非寺
量子位 | 公众号 QbitAI
大模型能打掼蛋吗?
这是清华唐杰的最新论文。

清华、北邮、智谱、博世AI团队联合研究表明,大模型不仅能打掼蛋,还会打麻将、德州扑克、Uno等8种棋牌。
不同的模型在不同棋牌类型上的表现也不同:
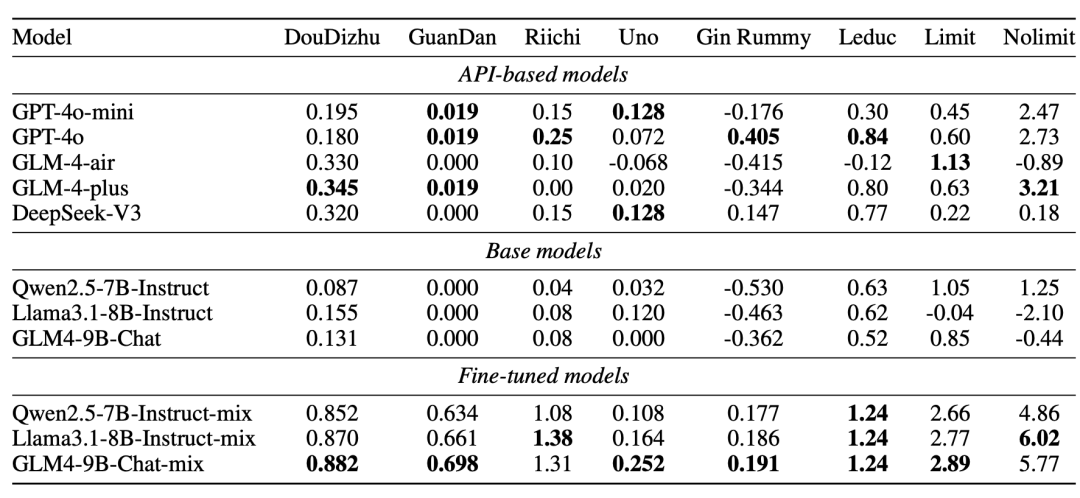
5种基于API的模型中,GPT-4o综合表现最佳,但在斗地主上略逊于GLM-4-plus。
3类微调模型中,GLM4是牌桌上的“全能型选手”,斗地主、掼蛋、Uno全都不在话下。
而Llama3.1更像是专攻某些领域的“冷门高手”,在立直麻将和无限注德扑中表现抢眼,但在斗地主、掼蛋等游戏中略逊于GLM4。
值得注意的是,模型一旦学会打牌,它的通用能力可能会略有下降,但只要加入一定量的通用数据,这个问题就能得到缓解。
难道是玩游戏玩的不会学习了?
所以大模型是如何一下学会这么多游戏的?
轻松掌握8种棋牌游戏
在游戏选择上,研究团队基于受欢迎程度、复杂性、高质量模型及数据的可获得性选出了8款纸牌游戏:
斗地主、掼蛋、立直麻将、Uno、金拉米、Leduc扑克、限注德州扑克和无限注德州扑克。
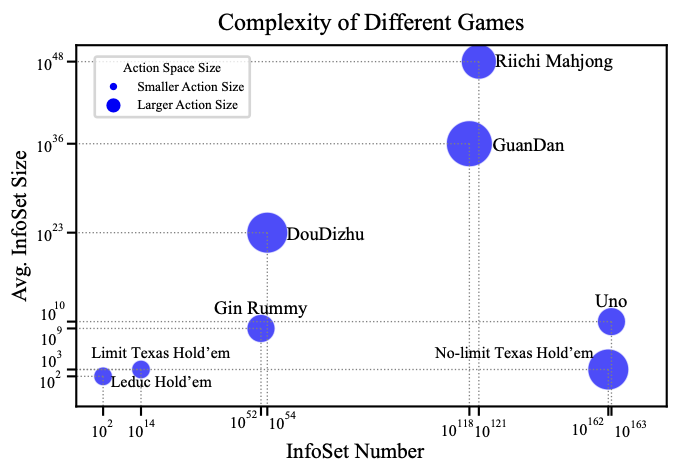
首先从博弈论的角度来看,这些游戏都属于非完全信息多人博弈。
简单来说,就是游戏中有多个玩家,每个“玩家”都看不到其他人的手牌,并且初始手牌和牌堆是随机发放的。
在非完美信息游戏中,由于信息是不完全、非对称的(例如扑克和麻将中对手的手牌和游戏剩余的底牌都是未知的),因此对于参与者来说许多不同的游戏状态看起来是无法区分的。
在2023年,腾讯AI Lab就针对打麻将提出了一种基于强化学习和遗憾值最小化的自我博弈技术。
这使得AI能从零开始自我学习和提升能力,并最终收敛到一个最强的混合策略。
同时考虑到传统的非完美信息搜索算法在麻将面前很难发挥太大作用,研究人员还基于乐观价值估计的思想,提出了一种高效的非完美搜索方法,使得AI能在海量隐藏信息的游戏状态中,实时调整当前策略,更好应对多变的战局。
但这次,研究团队选择采用现有的强大游戏AI来生成高质量的轨迹数据,并让大语言模型通过学习这些数据来掌握复杂游戏。
游戏基础,学习方法就不基础。
首先,研究团队让教师模型与对手进行对抗,以生成游戏交互数据。每场游戏都会根据实际情况,配备相应的教师模型和对手。
(需要注意的是,麻将没有教师模型。)
其次,根据不同游戏的复杂程度,每种游戏的对局次数也有所不同,斗地主、掼蛋和麻将的平均步数明显高于其他游戏。
尤其是掼蛋、麻将的步数更长,这是因为它们的对局本质上是由多个回合构成的。
例如掼蛋,其获胜规则要求玩家必须从2升级到A,游戏进程较长,自然需要更多的回合。
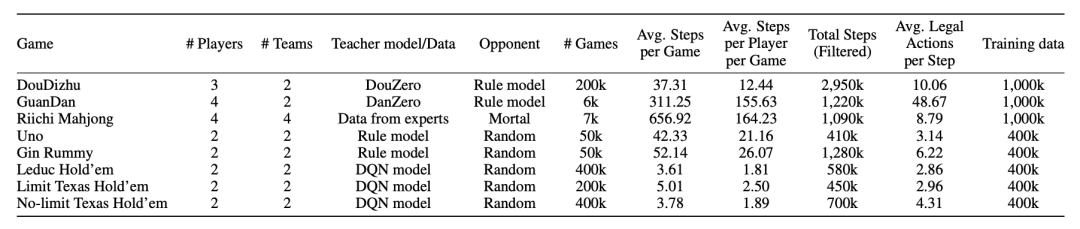
研究团队针对不同游戏的复杂度,设计了一套颇为“量体裁衣”的数据采集方案:斗地主、掼蛋和立直麻将由于玩法更复杂,各自收集了100万个训练实例,其余5款游戏则每种采样40万个。
随后,团队对三种不同类型的模型(Qwen2.5-7B、Llama3.1-8B 和 GLM4-9B)进行微调,以分析模型类型对性能的影响。
与此同时,他们还对参数规模从0.5B到14B的Qwen2.5进行微调,以评估模型规模对性能的影响。
在评估指标方面,不同游戏采用了不同的胜率度量方式:斗地主采用绝对胜率,掼蛋采用轮次胜率,其余6种游戏则使用奖励分数。
结果显示,随着训练数据量的增加,大模型在斗地主和掼蛋中的表现逐渐接近教师模型,颇有些“青出于蓝”的意味。
而在麻将中,即使没有可用的教师模型,大模型依然达到了与一款顶尖麻将AI相当的表现。
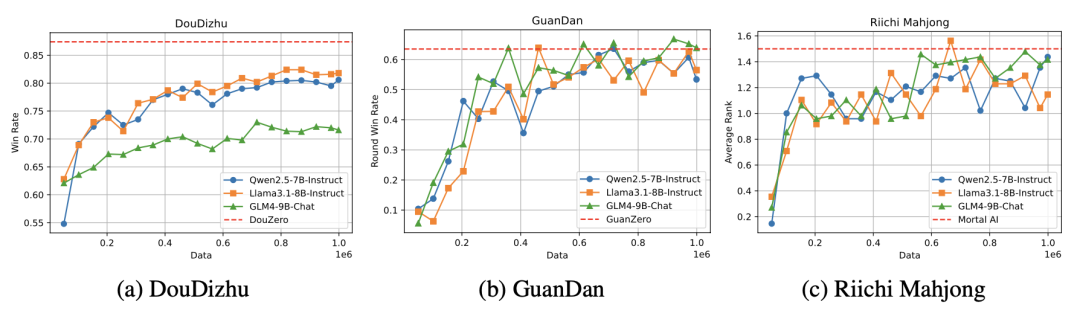
除此之外,研究者还观察到在斗地主中,GLM的性能明显不如Qwen和Llama,这是为什么呢?
为了分析不同模型在斗地主中的差异,团队进一步绘制了模型在扮演不同角色时的胜率。
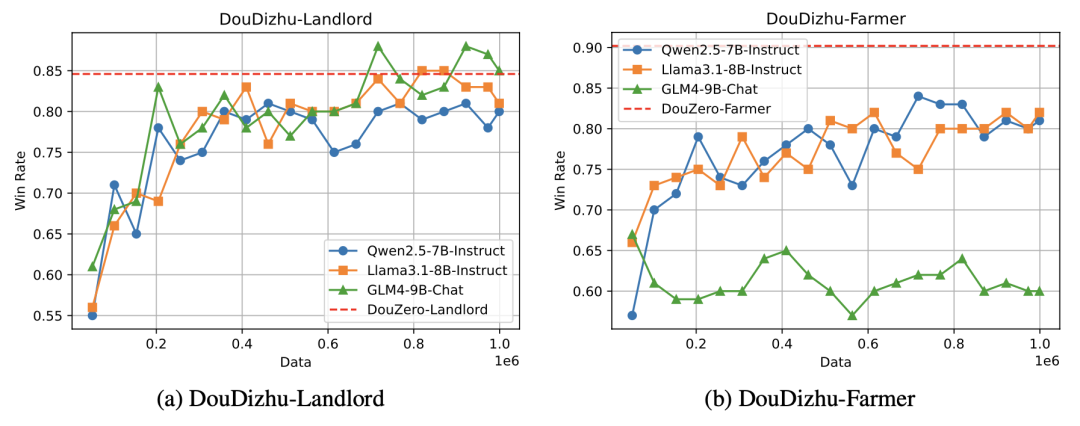
可以看出,GLM在扮演地主时表现优于Qwen和Llama,但在扮演农民时,表现较差。
这表明GLM未能有效平衡俩个角色之间的学习,更多地关注了地主角色,而导致农民表现较弱。
那为什么会出现这种差异呢?
原因是在进行数据过滤时,研究团队只保留了获胜方的数据。
斗地主中有一名地主和两名农民,当农民获胜时,双方的数据都会被保留。然而,很多情况下胜利可能主要依赖于其中一名农民的操作,而另一名农民的数据质量较低。
因此,训练数据中存在一些低质量的农民角色数据,导致农民角色的表现远低于其理论最高水平。
基于上述实验,研究团队大致确定了每种游戏收敛所需的数据量。
然后,他们按照这一数据量从各游戏的训练数据集中进行采样,并将数据合并,得到一个包含所有游戏数据的混合训练集。
具体而言,该组合数据集包含310万条数据,8种游戏的数据量分别为:70万、95万、65万、20万、5万、25万、20万和10万。
在此基础上,研究人员对语言模型进行混合训练微调,以评估其是否能够同时掌握多种游戏,并将微调后的模型与基于API的模型及基础模型进行对比。
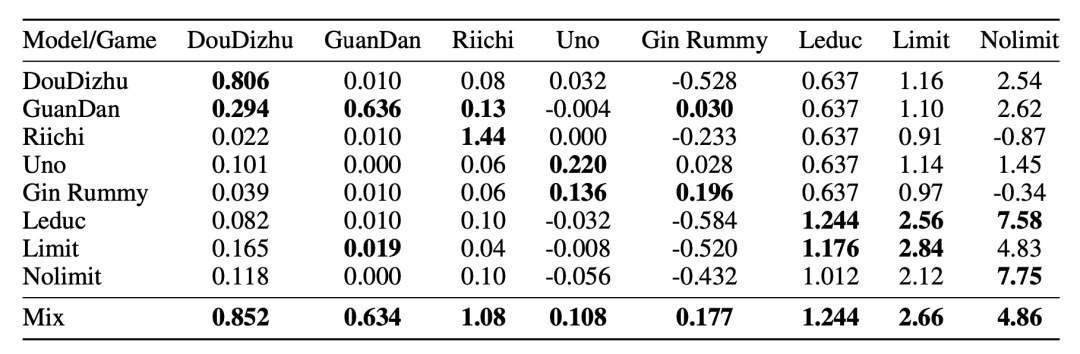
结果显示,所有基于API的模型在两款最复杂的游戏(掼蛋和麻将)上的得分相对较低,而在其他6款游戏上的得分较高。
值得一提的是,在5种API模型中,GPT-4o表现最佳,在大多数游戏中取得了最高分。
GLM和DeepSeek的模型在斗地主中的得分较高,或许是因为它们“从小耳濡目染”,对这款国民级游戏更“门儿清”。
与基于API的模型相比,3种基础模型在大多数游戏中的表现最差。
相比之下,微调后的模型表现最佳,尤其是在斗地主、掼蛋和日本立直麻将这些复杂游戏中的提升最为显著。
其中,3种微调模型在Leduc扑克上得分相同。
但综合来看,GLM4-9B-Chat-mix表现最为出色,在斗地主、掼蛋、Uno、金拉米、Leduc扑克和限注德州扑克上都位居第一。
Llama3.1-8B-Instruct-mix最擅长Uno、Leduc扑克和无限德州扑,而Qwen2.5-7B-Instruct-mix则相对表现较弱。
为了进一步探究不同游戏之间的相互影响,研究团队将仅在单一游戏上微调的模型,在其余7种游戏上进行了评估。
可以看到,与在其他游戏上训练的模型相比,掼蛋上训练的模型在斗地主上的表现也不错,这表明掼蛋对斗地主有正向加成。
此外,Leduc扑克、限注德扑和无限注德扑这3款游戏之间也存在正向影响。
接着,团队还把只在单一游戏上微调的模型和在所有游戏上混合微调的模型进行了对比。
结果发现,相较于单独微调的模型,混合微调模型在这两款游戏上的表现进一步提升。
互相切磋完牌技就是不一样。
不过,有趣的是,与单独微调的模型相比,混合微调模型在其他6款游戏上的表现有所下降,这说明斗地主、掼蛋和其他6款游戏之间存在一定的冲突。
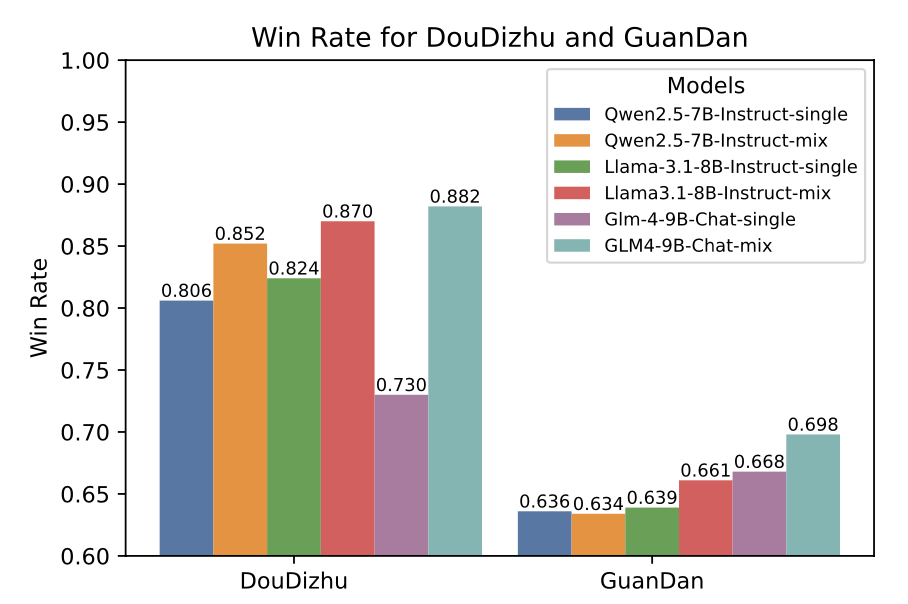
由此可见,在大模型可以同时掌握多种复杂棋牌游戏的基础上,规则相似的游戏之间会互相增强表现,而规则差异较大的游戏则可能出现性能上的冲突。
那大模型会打牌之后,它的通用能力会不会有什么变化呢?
针对这一问题,团队在知识问答(MMLU-Pro)、数学(Math-500)和编程能力(HumanEval)上进行了测试。
结果发现,在所有游戏上微调的混合模型,其通用能力出现了显著下降。
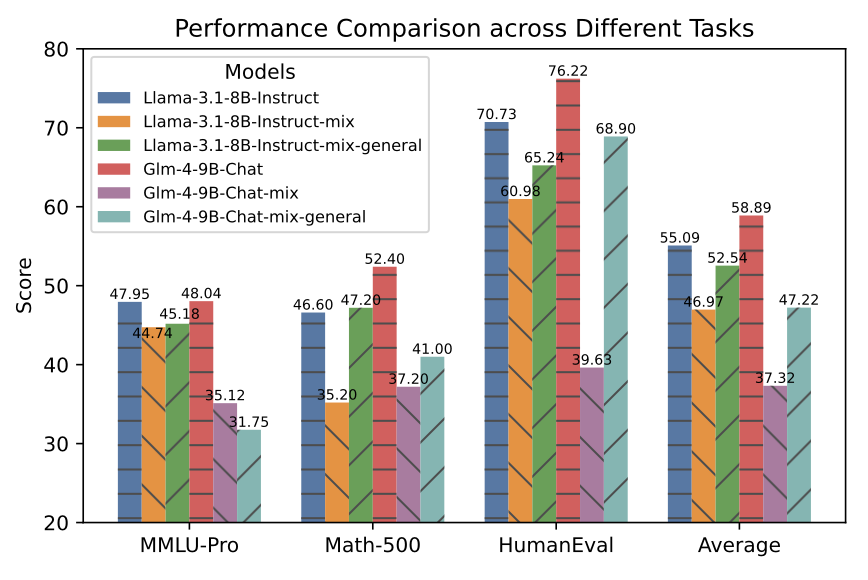
好消息是,团队进一步用通用数据对游戏模型进行微调,模型的通用能力在一定程度上得到了恢复。
这下是既能打牌又能学习了。
参考链接:https://arxiv.org/abs/2509.01328
一键三连「点赞」「转发」「小心心」欢迎在评论区留下你的想法!
— 完 —
]article_adlist-->专属AI产品从业者的实名社群,只聊AI产品最落地的真问题 扫码添加小助手,发送「姓名+公司+职位」申请入群~
扫码添加小助手,发送「姓名+公司+职位」申请入群~
进群后,你将直接获得:
👉 最新最专业的AI产品信息及分析 🔍
👉不定期发放的热门产品内测码 🔥
👉内部专属内容与专业讨论 👂
]article_adlist-->🌟 点亮星标 🌟科技前沿进展每日见
]article_adlist--> 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP
资炒股门户提示:文章来自网络,不代表本站观点。